
스택(Stack)
개념
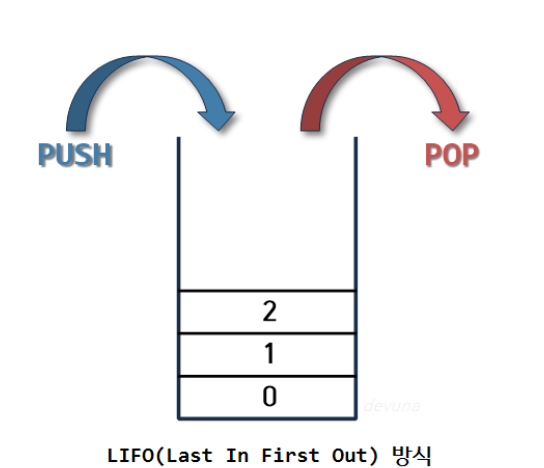
스택이란 쌍하 올린다는 것을 의미 따라서 스택 자료구조라는 것을 책을 쌓는 것처럼 차곡차곡 쌓아 올린 형태 자료구조
특징
스택은 같은 구조와 크기의 자료를 정해진 방향으로만 쌓을 수 있다.
스택에서 top을 통해 삽입하는 연산을 push 삭제하는 연산을 pop이라고 하며 스택은 가장 마지막에 삽입된 자료가 먼저 삭제되고
후입선출(LIFO) 방식구조 라고 한다.
코드
public class Stack<T> {
private ArrayList<T> items;
public Stack() {
items = new ArrayList<>();
}
public boolean isEmpty() {
return items.isEmpty();
}
public void push(T item) {
items.add(item);
}
public T pop() {
if (isEmpty()) {
throw new EmptyStackException();
}
return items.remove(items.size() - 1);
}
public T peek() {
if (isEmpty()) {
throw new EmptyStackException();
}
return items.get(items.size() - 1);
}
public int size() {
return items.size();
}
}- isEmpty(): 스택이 비어 있는지 여부를 확인하며 스택이 비어 있으면 true를, 그렇지 않으면 false를 반환
- push(T item): 주어진 요소를 스택의 맨 위에 추가
- pop(): 스택의 맨 위에 있는 요소를 제거하고 반환
- peek(): 스택의 맨 위에 있는 요소를 반환
- size(): 스택의 현재 크기를 반환
큐(Queue)
개념
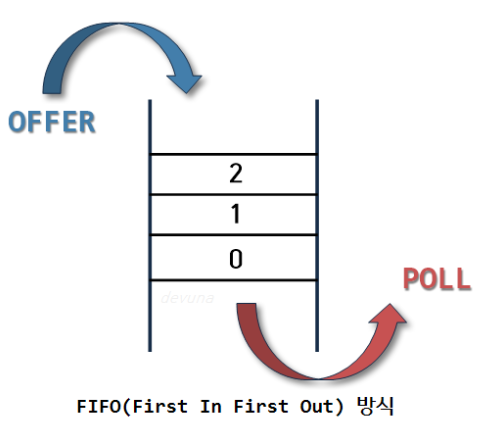
사전적인 의미로는 줄, 혹은 줄을 서서 기다리는 것을 의미함으로 일상생활에서 놀이동산에 줄을 서서 기다리는 것, 은행에서 먼저 온 사람의 업무를 창구에서 처리하는 것 처럼 선입선출(FIFO)방식 구조라고 한다.
특징
큐는 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서 삭제 작업이 양쪽으로 이루어진다.
삭제연산만 수행되는 곳을 프론트(Front) 삽입연산만이 이루어지는 곳을 리어(rear) 정하여 수행되는데 이때 큐의 리어에서 이루어지는 삽입연산을 인큐(enQueue) 프론트에서 이루어지는 삭제연산을 디큐(deQueue) 라고 한다.
코드
public class Queue<T> {
private ArrayList<T> items;
public Queue() {
items = new ArrayList<>();
}
public boolean isEmpty() {
return items.isEmpty();
}
public void enqueue(T item) {
items.add(item);
}
public T dequeue() {
if (isEmpty()) {
throw new EmptyStackException();
}
return items.remove(0);
}
public T peek() {
if (isEmpty()) {
throw new EmptyStackException();
}
return items.get(0);
}
public int size() {
return items.size();
}
}- enqueue(T item): 큐의 맨 뒤에 요소를 추가
- dequeue(): 큐의 맨 앞에서 요소를 제거하고 반환
- peek(): 큐의 맨 앞에 있는 요소를 반환
이진탐색(Binary search)
개념
정렬된 배열에서 특정 값을 찾는 알고리즘을 의미함으로 절반씩 분할하여 탐색함으로 주어진 배열이 정렬된 상태임을 보장하면 매우 빠르다.
- 시간복잡도 : O(logN)
예시
아래와 같이 10개의 데이터가 있는 데이터셋에서 값이 63인 데이터를 찾아보자.
1 12 14 27 33 42 45 52 63 70
- 중앙값을 찾기
크기가 10이므로 (1+10)/2 = 5 이므로 중앙값은 5번째이다.
-> 중앙값 = 5번째(33)
- 찾고자 하는 데이터와 중앙값을 비교
타깃 데이터(63) > 중앙값(33) 이므로, 오른쪽 데이터셋을 선택한다. - 데이터셋 재설정
이제 6번째(42)부터 10번째(70)까지 탐색한다. - 4 4 5 6 7
2 5 2 3 0
(위의 과정을 반복한다.)
- 중앙값 설정 : 중앙값 = 52
- 데이터 비교 : 63 > 52 이므로 오른쪽 데이터셋 선택
- 데이터셋 재설정 : 9번째(63)부터 10번째(70)까지 2개의 데이터셋이다.
- 6 7
3 0 - 중앙값 설정 : 다음 데이터셋은 9번째~10번째 이므로 중앙값은 (int)(9+10)/2 이므로 9이다.
- 데이터 비교 : 타깃 데이터(63) == 중앙값(63) 이므로 탐색 완료!
'CS > DataStructure&Algorithms' 카테고리의 다른 글
| [Algorithms & Data structure] Binary Search VS HashMap (0) | 2024.06.17 |
|---|---|
| [Algorithms & Data structure] Dynamic Programming (2) | 2024.06.10 |
| [Algorithms & Data structure] 탐욕(Greedy) 알고리즘 (1) | 2024.06.10 |
| [Algorithms & Data structure] 시간복잡도 (2) | 2024.06.10 |
| [Algorithms & Data structure] DFS & BFS (0) | 2024.06.10 |